To lock, or not to lock
TL;DR #
As I've promised you in my previous post, I made TLSnappy balance and handle requests a little bit better.
Data flow #
For leveraging all available CPUs TLSnappy runs multiple threads that are each picking and processing tasks from their dispatch queues, one by one. Tasks are created from node's event-loop in following cases:
- Data comes from client and should be decrypted
- Data from server should be encrypted
So, as you can see, each thread is receiving data from it's inputs (either
encrypted or clear) and/or emitting data to it's outputs. This pattern
apparently requires a lot of data transfer to and from worker threads and
requires storing (buffering) that data in some temporary storage before
processing it.
To my mind, best structure to fit this needs is Circular (Ring) buffer. Because it's fast, can be grown if more than it's current capacity needs to be held.
The Naive version of it was good enough to try out things, but it wasn't supposed to be run in a multi-threaded concurrent environment - all access to this buffer can take place only in a critical section. This means that at any time only one thread may access the ring's methods or properties. You might think that this doesn't make difference, but, according to Amdahl's law, reducing time spent in non-parallelizable (sequential) parts of application is much more critical for overall performance than speeding up parallel parts.
Lock-less ring buffer #
Removing locks seemed to be essential for achieving better performance, however a special structure needs to be used in order to make a ring buffer work across multiple CPUs. Here is the structure I chose for it:
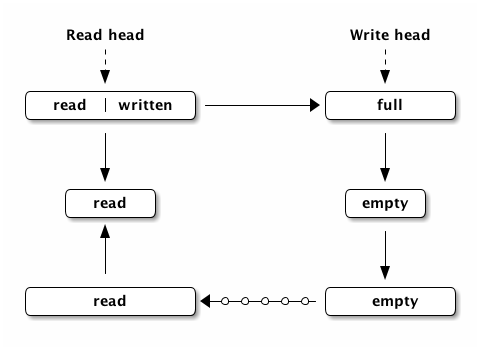
Ring consists of pages that're forming circular linked list, each page has two
offsets: reader (roffset) and writer (woffset). And there're two special
pages (which could be the same one actually): reader head (rhead) and writer
head (whead).
Initially the ring contains only one page which is rhead and whead at the
same time. When the producer wants to put data in - it goes to the whead,
copies data into the page, increments woffset and if the page is full - it
create a new page, or reuses an old one that doesn't contain any un-read data.
Consumer takes rhead reads up to woffset - roffset bytes from it, increments
roffset and moves to the next page if roffset is equal to the size of the
page.
So here are benchmarks:
Without lock-less ring:
Transactions: 200000 hits
Availability: 100.00 %
Elapsed time: 47.90 secs
Data transferred: 585.37 MB
Response time: 0.02 secs
Transaction rate: 4175.37 trans/sec
Throughput: 12.22 MB/sec
Concurrency: 98.79
Successful transactions: 200000
Failed transactions: 0
Longest transaction: 0.09
Shortest transaction: 0.00With lock-less ring:
Transactions: 200000 hits
Availability: 100.00 %
Elapsed time: 47.37 secs
Data transferred: 585.37 MB
Response time: 0.02 secs
Transaction rate: 4222.08 trans/sec
Throughput: 12.36 MB/sec
Concurrency: 98.83
Successful transactions: 200000
Failed transactions: 0
Longest transaction: 0.12
Shortest transaction: 0.00As you can see, performance hasn't greatly improved and is actually almost beyond statistical error (which means that results are nearly the same). However these are results for small 3kb page, lets try sending some big 100kb buffers.
Without lock-less ring:
Transactions: 100000 hits
Availability: 100.00 %
Elapsed time: 64.06 secs
Data transferred: 9536.74 MB
Response time: 0.06 secs
Transaction rate: 1561.04 trans/sec
Throughput: 148.87 MB/sec
Concurrency: 98.59
Successful transactions: 100000
Failed transactions: 0
Longest transaction: 1.93
Shortest transaction: 0.00With lock-less ring:
Transactions: 100000 hits
Availability: 100.00 %
Elapsed time: 58.73 secs
Data transferred: 9536.74 MB
Response time: 0.06 secs
Transaction rate: 1702.71 trans/sec
Throughput: 162.38 MB/sec
Concurrency: 98.98
Successful transactions: 100000
Failed transactions: 0
Longest transaction: 0.19
Shortest transaction: 0.00Wow! That's much better - about 9% performance improvement.
Instruments #
Still TLSnappy's performance wasn't even close to what nginx is capable of
(~5100 requests per second). Thus it was necessary to continue investigation and
this is where Instruments.app comes into play, which is basically an UI for some
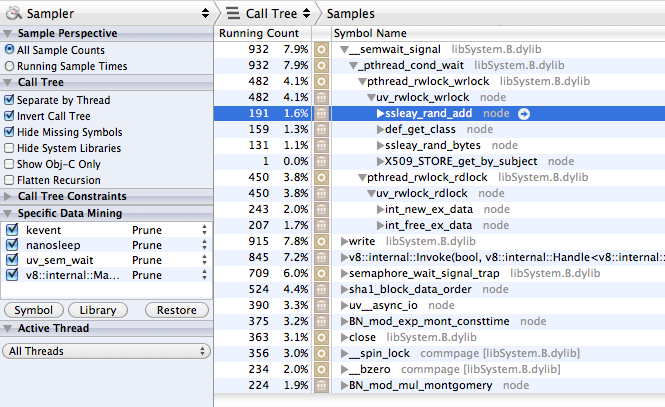
very useful dtrace scripts. I've run the CPU Sampler utility and this is what
the call tree looked like:
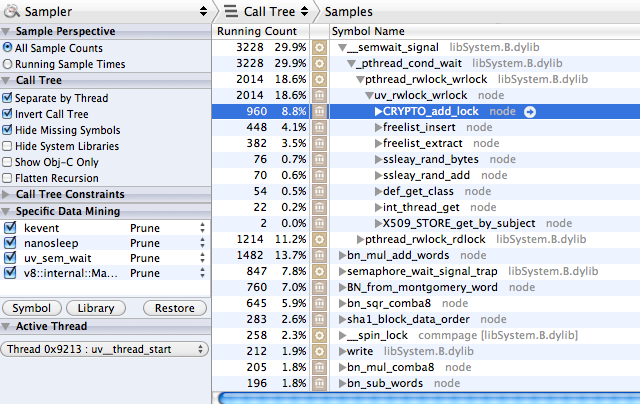
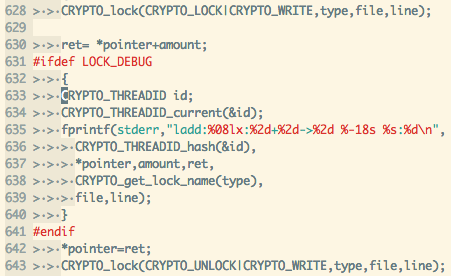
Obviously it spends almost 30% of time in synchronization between threads,
particularly in CRYPTO_add_lock function:
After modifying the code to use atomic operations, which are supported by almost
every CPU nowadays):
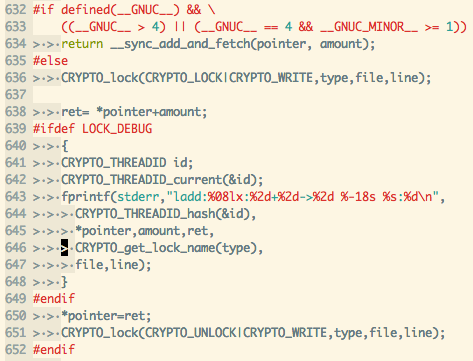
Call tree locked like this:
Results #
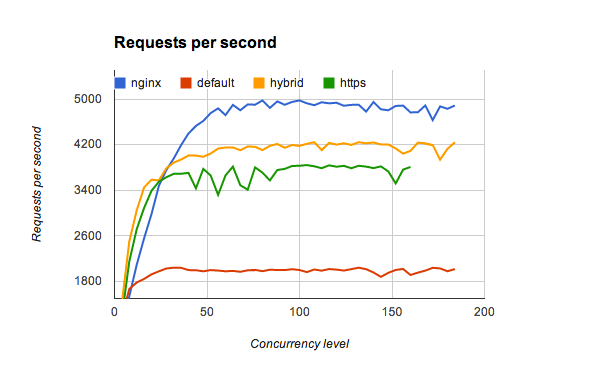
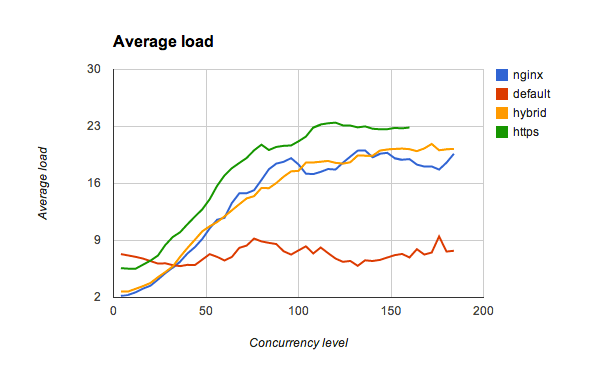
I've opened pull request for node.js and sent the same patches to the openssl-dev mailing list. With patched node and latest tlsnappy these are the benchmark results:
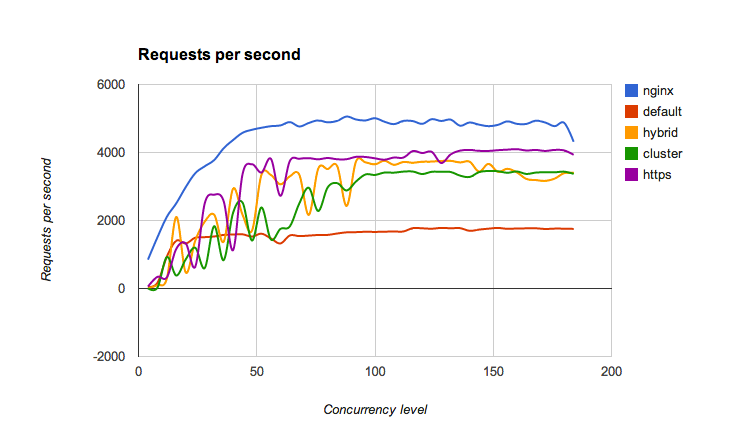
And that's without patches:
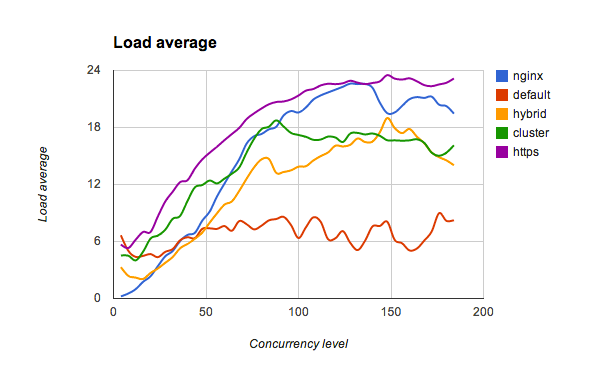
A little comment about curve names here:
default- one tlsnappy process with 16 threadshybrid- 4 tlsnappy processes with 4 threads eachcluster- 16 tlsnappy processes with 1 thread eachhttp- 16 node.js processes in cluster
The work is unfinished yet, but now I know that OpenSSL doesn't really behave well when used in multithreaded application.
- Previous: Benchmarking TLS, TLSnappy and NGINX
- Next: Candor returns