Deoptimize me not, v8
Compilers are awesome, right? If any programming concept may exist, it will probably be used in compiler implementation at some point. I am always amazed by my findings during v8 bug triaging or just random code exploration.
The interesting thing about v8 that I was always passionate about, but never truly understood, was the Deoptimizer. The idea here is that v8 optimizes code to make it run faster, but this optimization relies on assumptions about types, ranges, actual values, const-ness, etc. These assumptions imply that the optimized code won't run when these conditions are not met, since the compiler needs to "deoptimize" it by returning to the previous "no-assumptions" version of generated code when the assumptions are failing.
Technically it means that the compiler is in fact two compilers: a base compiler and an "optimizer". (Or even more, if we are talking about JSC and SpiderMonkey). The concept is quite sound and can yield incredible performance, but there is a nuance: the optimized code may be "deoptimized" in various places, not just at the entry point, meaning that the environment (local variables, arguments, context) should be mapped and moved around.
Stack machines #
To better understand what needs to be done and how things are happening let's consider a basic stack machine, like the one that we might use to interpret program instead of JIT compiling it.
Note that this stack machine and assembly below are just an output of some abstract compiler and has nothing do to with v8. Thus here only for demonstration purposes
push a
push b
push c
mul ; pop 2 values and push `arg0 * arg1`
push d
mul ; b * c * d
add ; pop 2 values and push `arg0 + arg`
ret ; pop and return valueThe interpreter will execute instructions one-by-one, maintaining the stack at every point.
Now we let's imagine some register machine (like x86_64), and write down the same program in assembly language. To make it a bit more interesting, consider that the target architecture has only two registers and the rest of the values need to be stored in memory (on-stack).
mov [slot0], a ; store value in 0 memory slot
mov rax, b ; store value in rax register
mov rbx, c ; store value in rbx register
mul rax, rbx ; rax = rax * rbx
mov rbx, d
mul rax, rbx ; rax = b * c * d
mov rbx, [slot0] ; load value from 0 memory slot
add rax, rbx ; rax = b * c * d + aThe instructions are executed one-by-one, maintaining the register values and memory slots.
In terms of our compiler, the former code is an unoptimized version of our program, and the latter one is optimized. In fact, this is a completely valid claim if we would like to run it on x86_64 platform, as assembly has much higher execution speed than interpreted code that needs to be emulated.
Suppose that the second mul instruction in assembly works only when the d
(which is in rbx register) is a small integer. Now if the execution will
reach the mul and find that there is a JavaScript string, it will just fail
to do the "right thing". This mul(num, str) operation will definitely require
some sort of type coercion, and could be easily handled by the interpreter.
Doing it in assembly will very likely be much more costly in terms of
performance. To deal with this the compiler inserts check instructions:
mov [slot0], a
mov rax, b
mov rbx, c
checkSmallInt rax
checkSmallInt rbx
mul rax, rbx
mov rbx, d
checkSmallInt rax
checkSmallInt rbx
mul rax, rbx ;
mov rbx, [slot0]
add rax, rbxSo in such an uncommon case, where the argument of mul is not a small integer,
this code should somehow be "deoptimized" from assembly code to the stack
machine and continue execution in the interpreted version. Here is the position
in the optimized code where it will stop:
mov [slot0], a
mov rax, b
mov rbx, c
checkSmallInt rax
checkSmallInt rbx
mul rax, rbx
mov rbx, d
checkSmallInt rax
checkSmallInt rbx <-----
mul rax, rbx ;
mov rbx, [slot0]
add rax, rbx...and position in unoptimized code, where would like it to continue:
push a
push b
push c
mul
push d
mul ; <-----
add
retHow could it do that? The simplest way is just to re-execute all code from the program's entry point using the input arguments. This solution is very limited though, because it is possible only if the optimized function was pure, or in other words had no instructions with side effects (like function calls, etc...).
The more general solution is to find all live values (the ones that may be used by later functions) at the deoptimization point, find their locations in both optimized and unoptimized code, and copy the values from the registers/memory to stack machine's slot.
This is exactly what the "deoptimizer" in v8 does. The main difference from our
imaginary example is that both unoptimized and optimized codes are in x86_64
assembly language.
Simulates #
Now we know what to do, but how is it actually implemented in v8?
These mappings are possible thanks to the special high-level instructions called
Simulates. This is how they look in the v8's high-level intermediate
representation (abbr. IR, see my EmpireNode talk for more info on the IRs):
v9 BlockEntry <|@
v10 Simulate id=3 var[3] = t8 <|@
v11 StackCheck changes[NewSpacePromotion] <|@
v12 UseConst t8 <|@
t13 ThisFunction <|@
t14 CheckNonSmi t3 <|@
t15 CheckMaps t3 [0x2e26d7019781] <|@
v16 CheckPrototypeMaps [...] <|@
v17 Simulate id=24 push t3, push t4, push t8, var[3] = t13 <|@
v18 EnterInlined middle, id=4 <|@
t54 PushArgument t3 <|@
t55 PushArgument t4 <|@
t56 ArgumentsElements <|@
v19 UseConst t1 <|@
t20 Constant ... <|@
v25 Simulate id=26 pop 1, push t19, var[3] = t2, var[4] = t20 <|@(Note that you can obtain such IR by running node.js with --trace-hydrogen
flag, which will print it out into the hydrogen.cfg or hydrogen-<pid>.cfg
file).
The thing is called Simulate with good reason. Strip away all other
instructions:
v10 Simulate id=3 var[3] = t8 <|@
v17 Simulate id=24 push t3, push t4, push t8, var[3] = t13 <|@
v25 Simulate id=26 pop 1, push t19, var[3] = t2, var[4] = t20 <|@...and we will see something that resembles... our simplified stack machine! Having a stack machine means that we could "simulate" it's state by executing instructions one-by-one. v8's has a couple of them:
var[index] = value- put a value in some on-stack slotpush value- push a value to a virtual stackpop count- popcountof values from the stack
Let's simulate some states out of the above sample:
v10: var = { 3: t8 }, stack = []
v17: var = { 3: t13 }, stack = [ t3, t4, t8 ]
v25: var = { 3: t13, 4: t20 }, stack = [ t3, t4, t19 ]Note that this "simulation" happens at compile-time, not when actually deoptimizing.
These states can be used to map the values from optimized to unoptimized code.
For example, if we would like to "deoptimize" at t56, we will have to find the
latest state which was at v17: var = { 3: t13 }, stack = [ t3, t4, t8 ], and
just place the present values into a proper stack slots and local variables (for
var ones).
With the --trace-deopt flag v8 will give us some insights on how it is doing
this:
**** DEOPT: outer at bailout #14, address 0x0, frame size 56
[deoptimizing: begin 0x341ad2082a49 outer @14]
translating outer => node=24, height=8
0x7fff5fbff3e8: [top + 72] <- 0xb7720f7d8b9 ; [sp + 96] 0xb7720f7d8b9 <an O>
0x7fff5fbff3e0: [top + 64] <- 0xb7720f7d8b9 ; rbx 0xb7720f7d8b9 <an O>
0x7fff5fbff3d8: [top + 56] <- 0x21ba55263fa9 ; caller's pc
0x7fff5fbff3d0: [top + 48] <- 0x7fff5fbff410 ; caller's fp
0x7fff5fbff3c8: [top + 40] <- 0xb7720f7d479; context
0x7fff5fbff3c0: [top + 32] <- 0x341ad2082ad9; function
0x7fff5fbff3b8: [top + 24] <- 0x341ad2004121 <undefined> ; literal
0x7fff5fbff3b0: [top + 16] <- 0x341ad2082ad9 <JS Function inner> ; literal
0x7fff5fbff3a8: [top + 8] <- 0xb7720f7d8b9 ; [sp + 24] 0xb7720f7d8b9 <an O>
0x7fff5fbff3a0: [top + 0] <- 0x341ad2004121 ; rax 0x341ad2004121 <undefined>Arrows here indicate the direction of movement. The output frame of the unoptimized code is on the left side, and on the right side - optimized code's values.
The mentioned frame is an on-stack structure used for storing the caller address
(to make return statements work), caller's frame address, and sometimes some
additional stuff (like JS context, this, arguments, and the function itself):
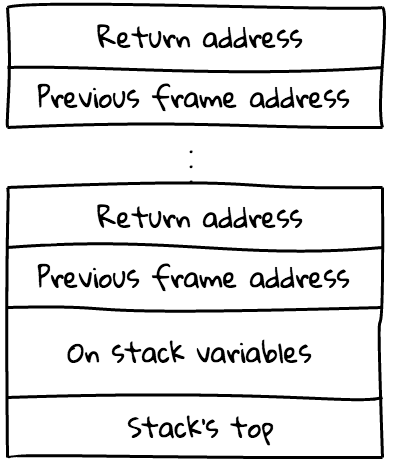
Ignoring all the internal frame things, the interesting part would be:
translating outer => node=24, height=8
0x7fff5fbff3a8: [top + 8] <- 0xb7720f7d8b9 ; [sp + 24] 0xb7720f7d8b9 <an O>
0x7fff5fbff3a0: [top + 0] <- 0x341ad2004121 ; rax 0x341ad2004121 <undefined>The high-level IR of the code that generated this trace contained:
0 0 v10 Simulate id=3 var[3] = t8 <|@
...
0 0 v17 Simulate id=24 push t3, push t4 <|@There is only one simulate instruction, and the state is: stack = [t3, t4].
(Sorry ignoring the local variables for this blog post).
Thus, the deoptimizer needs to put the values of the t3 and t4 instructions
into the stack slots. This information was stored ahead of time, and will be
looked up right when deoptimizing the code. Here, t3 was in the [sp + 24]
stack slot in the optimized code, and t4 was in rax. This process is called
a "frame translation". Afterwards the execution will be redirected to the
unoptimized code, which will just continue operating on the values at the place
where the optimized code has been "deoptimized".
Conclusion #
The "deoptimizer" is really an interesting tool, and it is one of the main cogs in Crankshaft's engine. This instrument helps the compiler in executing the dynamic-language code as if it had been written in C++, because it can always return to the slow unoptimized code with "true" JavaScript semantics.
Note that things are a bit more tricky with inlined functions, but this is a topic for another blog post.
Big kudos to:
- Vyacheslav Egorov
- Ben Noordhuis
- Jeremiah Senkpiel
for proof-reading this and providing valuable feedback.
- Previous: Cracking Cloudflare's heartbleed challenge
- Next: Side Projects